I am very pleased to announce the creation of the New York Dyalog APL Meetup group, details of which can be found online at https://www.meetup.com/New-York-Dyalog-APL-Meetup/. The meetup has been created and is organised by Paul Mansour, who is also sponsoring the venue for the inaugural meetup, scheduled for 6-9pm on Thursday February 7th, at Alley, 119 West 24th Street, New York. If you are interested in meeting APL users in the New York area, please join the Meetup group so that you will be notified of future events. Please sign up for events that you intend to attend so we know you are coming!
I am very pleased to announce the creation of the New York Dyalog APL Meetup group, details of which can be found online at https://www.meetup.com/New-York-Dyalog-APL-Meetup/. The meetup has been created and is organised by Paul Mansour, who is also sponsoring the venue for the inaugural meetup, scheduled for 6-9pm on Thursday February 7th, at Alley, 119 West 24th Street, New York. If you are interested in meeting APL users in the New York area, please join the Meetup group so that you will be notified of future events. Please sign up for events that you intend to attend so we know you are coming!
![]()
Meetup is a service used to organize online groups that host in-person events for people with similar interests, including programming languages. In addition to the New York group, there is also an APL Meetup group in Frankfurt which meets regularly. We welcome the creation of more local meetups! If you create one in your area, remember to inform us at Dyalog so that we can add a link from our event calendar, and arrange to stop by and speak when we are in your neighborhood!
The program for the meetup on February 7th is as follows:
6:00-6:30pm: Time for Networking
6:30-8:00: Morten Kromberg: New Ways of Working with APL
When you are busy solving problems, new technology can be an unwelcome distraction – but every now and again technologies appear which have the potential to make development, maintenance or distribution significantly easier. Morten will demonstrate some of the new ways of working with APL that have become available in the last few years, and also discuss likely features in the next couple of releases of Dyalog APL: 17.1 in Q2 of 2019 and 18.0 in 2020.
8:00-8:15 Short Break
8:15-9:00 Paul Mansour: Keeping it Simple – A Git Workflow for APLers.
Abstract: Git is great, but the newcomer can easily drown in a sea of commands and options. Git doesn’t tell you when or why to branch, when or why to merge or rebase, how to version your project or prepare a release. AcreFlow is a radically simplified Git workflow that answers these questions. It is implemented in Dyalog APL so you can branch, commit, and put out new versions directly from the APL session.
 Follow
Follow






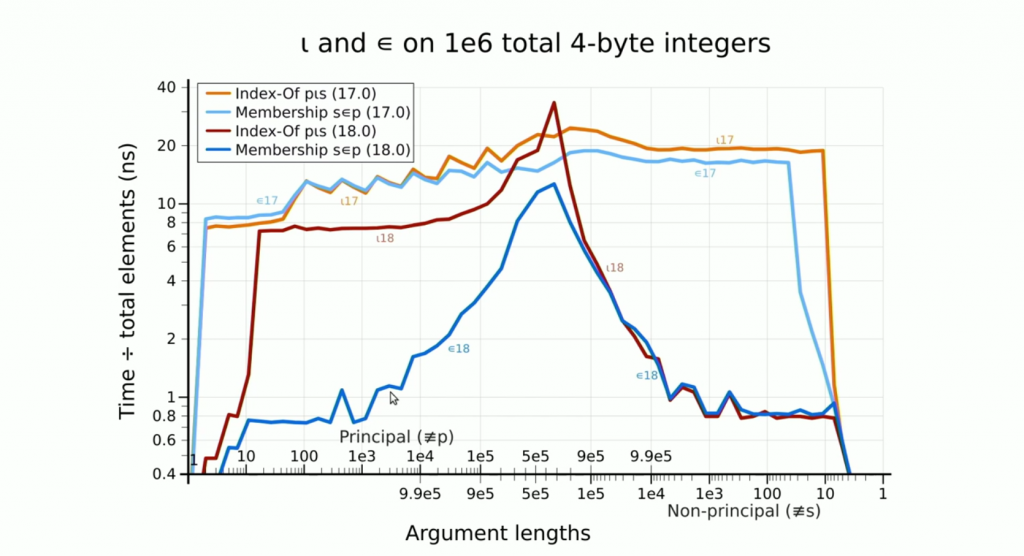
 By combining non-branching algorithms with vector instructions and a technique known as Robin Hood Hashing, Marshall is able to drive a modern CPU close to the theoretical maximum throughput, and in many cases spend less than one nanosecond searching for each item of an array.
By combining non-branching algorithms with vector instructions and a technique known as Robin Hood Hashing, Marshall is able to drive a modern CPU close to the theoretical maximum throughput, and in many cases spend less than one nanosecond searching for each item of an array.