

For more than 20 years, Causeway has been developing APL tools to produce automated publication-quality graphics and typesetting. They differ from most modern technologies on mainly two points:
- The API philosophy is to keep it simple and clean rather than complex and dirty, so that neat output can be generated with the bare minimum of coding
- The implementation is a forward-going state machine, so that arbitrarily complex inclusions can be created instead of having the engine restricted by the object hierarchy
Following the emergence of the .NET platform in the 2000s, these products were fully refactored into a single package called SharpPlot; this is delivered both as a cross-platform APL workspace and as a stand-alone .NET assembly that can be used outside the APL world. The major benefit of doing this was that 20 years of patched-in functionality could be incorporated into a more consistent and better documented API (see http://www.sharpplot.com) – a side-effect is that the .NET assembly generally performs an order of magnitude faster than its APL counterpart.
SharpPlot, which has until now only comprised the chart generation engine (refactored RainPro product) now also includes SharpLeaf (refactored NewLeaf product).
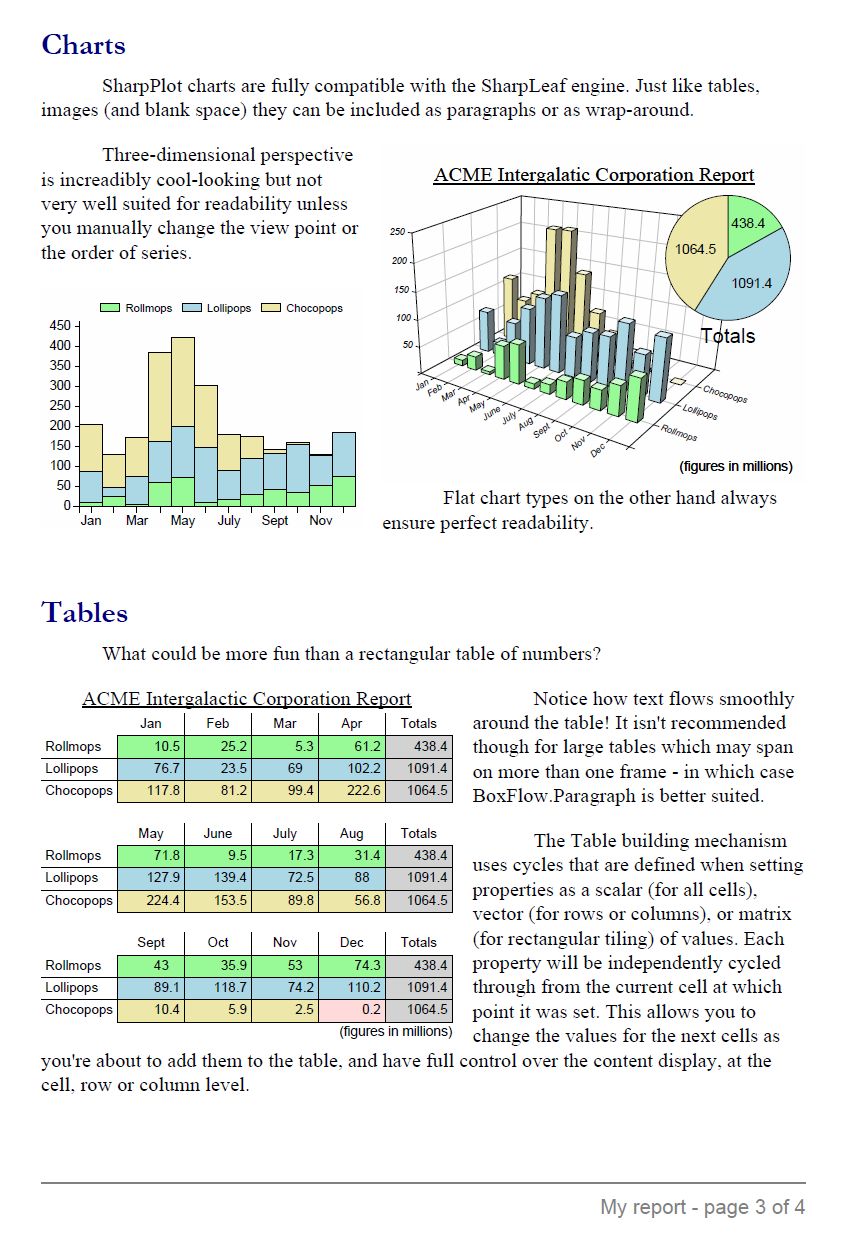
Sample report page (click to enlarge)
The main features of SharpLeaf are:
- Document Layout: a set of master pages defining paper size and rules for and color, boxes, images, fixed or parameterised text (for example, page number and date) etc.
- Paragraph Styles (word processing): fine typesetting control over the text flow (font, alignment, spacing, indents, bullets, etc.)
- Tables (spreadsheet processing): fine control over tabular presentation of data, including multi-page tables
- Inclusions: text flow around objects such as images, charts, tables, dropped capitals or blank space
SharpPlot version 2.70 includes the first (alpha) version of SharpLeaf. SharpLeaf should be considered as being in its alpha stage (its API could change) with a GA release scheduled to be included with SharpPlot version 3.00 (due Q3 2015). Users are encouraged to try this alpha product and not only report any bugs but also provide feedback on the API and request enhancements. Please note that the SharpPlot engine is not expected to suffer any bugs with the addition of SharpLeaf as it is an independent product.
The alpha version can be requested by sending an email to support@dyalog.com
 Follow
Follow





 The Dyalog Project Project
The Dyalog Project Project Data Binding – The Matrix / Waste Time with John Daintree
Data Binding – The Matrix / Waste Time with John Daintree