Blog post from presentation by Roberto Minervini with 4 of his students; Arianna Greco, Samuele Luigi Di Gioia, Kariman Admed and Silvana Maria Belén Colman Cabrera – all from Liceo Classico S.M. Legnani, a Public Secondary School.
By Vibeke Ulmann #Dyalog15
Getting the message of the power of Dyalog APL to young people, is one we have worked with for many years, as we need to recruit the next generation of APL programmers into our community.
Today was exceptional for the Dyalog User Meeting here in Sicily, as we had the pleasure of welcoming 19 young students – all around the age of 14 – who have been taught Dyalog APL for the purpose of using it for Maths.
Roberto Minervini has a background as an APL programmer, having worked 5 years in APL Italiana. Last year he left the Company to follow his dream of becoming a teacher.
He persuaded the school to let him teach a Dyalog APL class, and a team of 25 young people enrolled in extra classes after School in order to learn the language.
The presentation they gave today was enourmously fun with video clips with music, dancing and general ‘chaos’, which – from my point of view – seems to be the best way to have fun whilst learning a new (programming) language.

From Roberto’s point of view, he told us that we are faced with some serious issues when it comes to teaching our young people. There is increased competition between Schools to produce good results (i.e. higher number of students with high marks), there is a rigid curriculum which has to be followed, and it does not allow pupils to choose subjects they are interested in, or think would be fun. ‘Bad results’ is punished by ‘Bad marks’, which further de-motivates students. Bascially, today’s school and teaching is using methods that were developed for the age of Industrialiam. Whilst politicians have tried to introduce the concept of La Buona Scuola (The Good School) in Italy, there is confusion between what the goals and intentions of the Poitics behind the concept is, and how the teachers experience their everyday work.
Having used APL for many years, Roberto knows that APL is a ‘Tool of Thought’, and he decided that it would be better to try an engage the students in solving mathematic problems than teach them straight forward ‘maths by the book’.
Taking their offset in Kakuro – a Maths game which is the equivalent of a Cross Word puzzle, and an article written by Dan Baronet, as well as using other ‘guru’s from the world of teaching, writing and illustration/drawing- the class set to work.
According to Arianna, “we have no computer classes at school, so this was a completely new experience for all of us. We met once a week at lunch to discuss our progress and we quickly realised that with APL you can codify logic. I have personally found the language of the future!”
Kariman said, ” We started the project without any money at all – and although it was a bit strange to learn the APL squiggles – once you grasped them, it was fun.”
Roberto stated that in today’s society, failure is considered to be bad – and is hence punished with bad grades. The result is that pupils give up, and do not learn enough mathematics. On the other hand, we also know that in Technology and Science, failure is considered a good thing, because it forces you to learn new things and find new ways. So by implementing this approach instead, we were effectively “building the road as we walked on it.”.
According to Roberto, “We also took our offset in the book “A Matematician’s Lament” – by Paul Lockhard – which supports intuitive learning of math. Maths is really an ‘art’ – but today is taught in a boring way, with fixed exersizes and no real problems to solve.”
Samuel said that, “How to solve a problem involves deduction versus Induction.”
The process the class used for learning to solve problems using Dyalog APL was this:
If you cannot solve a problem – then there is an easier problem you can solve, so go find it!
However, Roberto warned, when teaching APL do NOT start with symbols. Learning APL is a Journey and once you have started this journey and apply it to learning Mathematics, maths almost becomes Utopia. The trick is to start with Key Words and key symbols, then practise and continue to practise, until it become ‘natural’.
Asked about what is the coolest thing about APL – the answer was a unanimous: It can do things by ilself!
Asked about what the biggest challenge had been, the answer was ” To learn the language and try to use it at home. You learn APL by using it, not by describing it!”
The students had also found that problems presented in the Programming contest 2015 had been helpful.
I can only encourage our blog readers to check back on the Dyalog website when the Videos from Dyalog’15 are posted and enjoy the presentation from Roberto and his pupils.


 Follow
Follow

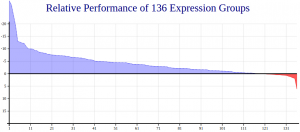 Core Performance
Core Performance Cross-platform User Interfaces
Cross-platform User Interfaces Cross-platform File Functions
Cross-platform File Functions